
Firebase Genkit
At Jsconf 2025, held in Madrid, I discovered an interesting library during one of the workshops: the Firebase Genkit framework.
This open-source library developed by the Firebase team at Google, although not limited to its ecosystem, offers a straightforward and frictionless solution. Compatible with JavaScript, TypeScript, and Go (in beta), and with support under development for Python, it is designed to be ultra-lightweight, strongly typed, and fully code-oriented. It does not require cumbersome configurations or rigid structures: you simply implement it and start building.
What really caught my attention was its philosophy, fully focused on product development. Its design allows for faster building and launching, eliminating friction and optimizing the workflow from the very beginning.
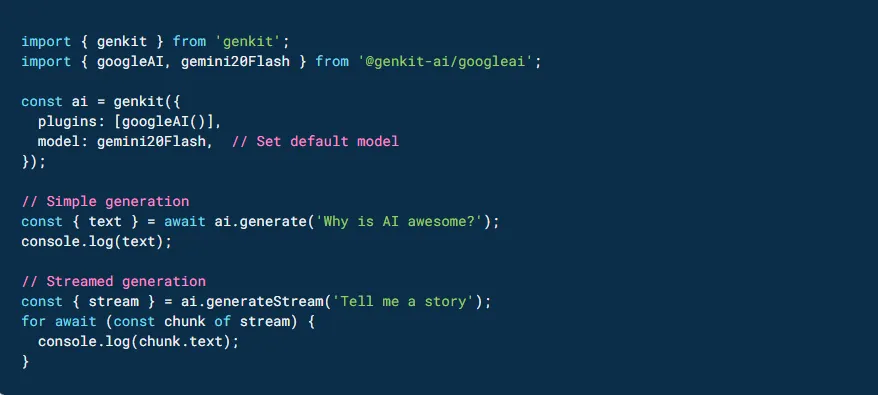
What makes Firebase Genkit stand out?
- Absolute simplicity: everything is designed so you can start developing without barriers.
- Ultra lightweight and scalable: optimized for performance without sacrificing capabilities.
- Production-ready: from the very beginning, it’s ready to integrate into real-world environments.
- Large plugin ecosystem: broad compatibility with LLMs and vector databases.
- CLI and local UI: allows you to run and test the framework without external deployments. With an intuitive interface and an integrated playground, it facilitates real-time debugging and experimentation, accelerating development.
- Evaluation system: includes an evaluation suite that lets you define custom criteria or choose preset values. You can also use LLMs to automatically validate responses.
- Observability and monitoring: provides monitoring and execution flow analysis tools through the UI.
- Prompts: prompts are pure code. You can define the input type, variables, and output format based on Zod (natively) for validation. This makes it easier to create your own library of reusable prompts.
It’s a solid foundational approach, but from my point of view, it does have some shortcomings. For example, in the documentation and resources reviewed, there’s no mention of any memory management system beyond vector databases. In particular, it doesn’t offer any specific solution for short-term memory management. However, there’s nothing stopping you from storing executions in a JSON and gradually incorporating them as part of the context.
It incorporates a system for agent development, where it does introduce more types of memory. However, this functionality is still in a fairly early stage of development.
From my point of view, for now, this library stands out in applications without a traditional backend, where its lightweight nature and easy integration allow for agile development without complex infrastructures. Mainly in applications without a traditional backend, where its lightweight nature and easy integration enable agile development without complex infrastructures. It stands out in Single Page Applications (SPA), mobile apps without a backend, chatbots connected to APIs, or real-time data processing systems using AWS Lambda functions or serverless environments.
It’s definitely a library I’ll keep in mind, and I recommend considering it. If you’re interested in learning more, I recommend checking out its official documentation, its GitHub repository, and of course, its community on Discord.